前回まで、打者の打球価値について、主に角度の平均値からの影響について検討し、たまにそれを速度の平均値と比較してきました。ここからは角度と速度という打球の特徴を表す2つの数値について、平均だけでなく分布の広がりを含めて評価することの重要性を見ていきます。データはStatcastから。
なぜ分布の広がりを考慮する必要があるかについては、前回書いたように、Eli Ben-Poratがよい説明を既に与えてくれています。
Eli Ben-Porat,
Mike Trout, Statcast Darling, 2018
https://www.fangraphs.com/tht/mike-trout-statcast-darling/
ここでは、角度と速度の分布の広がりを考慮することは、それらの数値と打球の得点価値との関係を考える上で、重要となりうることが議論されています。図を使って大まかに見ていきましょう。下はMLB15-18で打球角度2.5°ずつに打球を分けてその価値 (wOBAcon/xwOBAcon) と打球数 (N) を示しています。これは平均的な打者の角度に沿った打球の価値と数の分布と考えることができます。 おかしなピークは、正確に測定できなかったために推定値を入れている部分でしょう。
ここで、分布の中心に注目しましょう。 価値の分布 (wOBAcon/xwOBAcon) と打球数 (N) の分布との中心は比較的近いところにあります。これは、 打者が価値の高い領域に合わせて打球角度を合わせることができている、と言えるかもしれません。
次に分布の広がりを見ると、打球数のほうが価値に比べて、裾がなだらかに広がっています。これは、打球価値分布の裾に位置する価値の低い、あまり打ちたくないような打球が、それなりに生じているということです。このため、打球角度の広がりを小さくすれば、価値の分布の裾に位置する価値の低い打球を減らし、中心近くのより価値のある打球が多くなる可能性がありそうです。
別の見方をしてみましょう。とても極端な例として、0°と40°の2つの打球を打った選手と、20°の打球を2つ打った選手がいるとします。この場合、この二人の平均は20°ですが上の打球価値の分布を見ると、打球価値は後者のほうが大きく上回っていることがわかります。平均が同じであった場合、より平均の周りに打球が集まっている方が打球価値が高そうです。
下は同じように打球速度について、価値と頻度の分布を示しています。
速度の場合では、打球数のピークは打球価値のピークとは一致していません。価値がほぼ飽和する105 mph以上と比べると、5-15 mph程度低いところに打球数のピークはあります。価値の高い部分を多くするためには、もちろん平均速度を上げることでも可能ですが、価値の分布を両側に広くすることでも実現できる可能性がありそうです。
また極端な例を考えてみましょう。110 mphと70 mphの2つの打球を打った打者と、90 mphの2つの打球を打った打者を考えてみます。この場合、平均はいずれも90 mphですが前者の打者の方がかなり打球価値が高くなります。これは、70 mphと90 mphでは打球価値あまり変わらず、110 mphでは非常に価値が高いためです。この場合は平均が同じであれば、それぞれの打球が平均から離れている傾向があった方が打球価値が高くなりそうです。
重要なことは、打球価値と、角度あるいは速度との関係は単純な比例関係にあるわけではない、ということです。このため、価値と角度/速度の関係は平均を使うだけではうまく捕らえられません。 分布の形状や極端な例から考えてみると、平均に加えて広がりを考えることで、この関係性を評価に取り込める可能性がありそうです。では、角度や速度の広がりを考慮して、各打者の評価に役立つかを簡単な方法で調べてみましょう。
# 標準偏差
まず、広がりを表現する基準が必要になりますが、以後は標準偏差 (Standard deviation: SD) を使います。これは基本的には、データの中の一つ一つの数値が、平均を中心としてどれくらいばらついているか、離れているか、を示すような数字です。細かくは教科書でも見てもらうとして、とりあえずイメージだけ見てみましょう。下の例では平均値が同じ (12.5) で、SDが異なる分布 (a = 29, b = 21) を示しています。
SDが大きいほど各データは平均から離れている傾向が強いため、分布は幅が広く、中心部分が低いような形状になります。SDは分布の広がりを表現する数値として、良い性質を持っており非常によく使われ、前述したEli Ben-Poratの記事でもSDを広がりを示す数字として採用しています。
# 年度間相関
打者の評価に役立つかどうか、ということを調べる前提として、打者間でどの程度一貫した差が見られるか、という点が重要になります。これは、仮に、打球の結果に影響があったとしても、打者の間で見られる差が偶然の結果であれば、打者の評価には使えないためです。これを調べるために最もよく使われるのは年度間相関でしょう。MLB 2015-2018で連続した年度で200打球 (BBE) 以上の打者について、年度間で相関を調べました。下は散布図で示しています。
そこそこ以上に相関はありそうです。相関係数は下のようになりました。比較のため、同じ期間でのwOBAconの相関係数も示しています。
角度と速度の平均や、角度のSDでかなり高い相関が見られました。これらの相関は打撃系の指標としてはかなり高い部類だと言っていいと思います。速度のSDはやや相関が小さいですが、それでもwOBAconと大差無い程度には相関が出ています。wOBAconについては打者からコントロールが難しい要因がある (守備や打球の細かい方向など) のに比べて、打球の速度と角度にはそれらの影響がないため、打者から見てコントロール可能な部分が大きいのかもしれません。
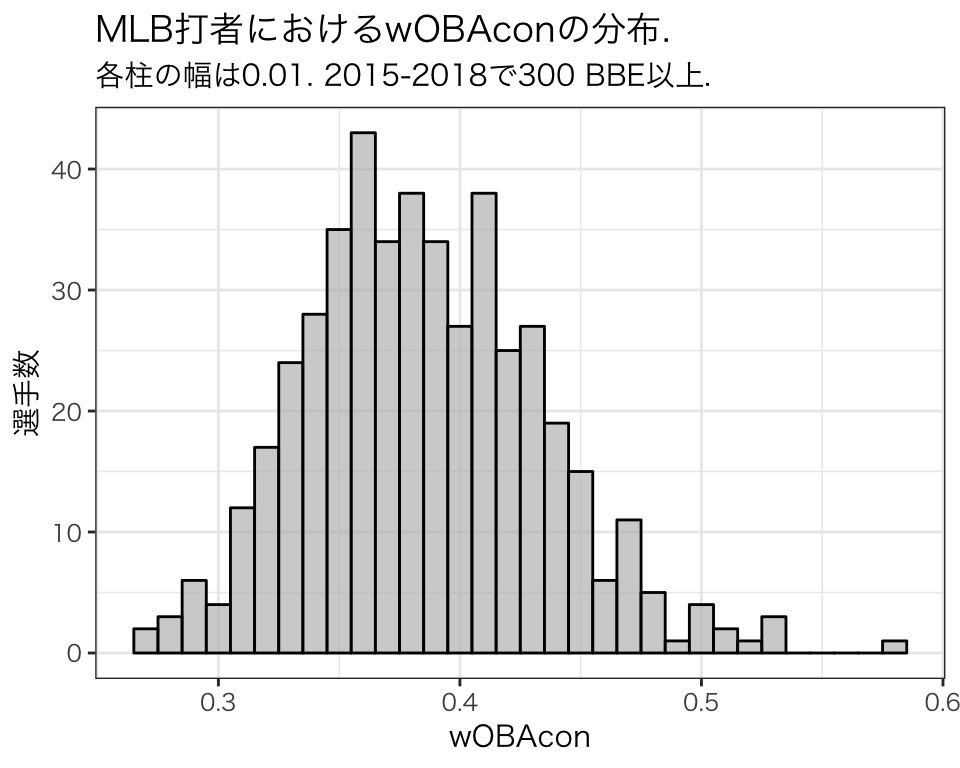
MLB15-18での通算で300BBE以上の打者における、それぞれの数値をヒストグラムで示しておきます。
次に、打撃結果への影響を調べてみましょう。
# 角度分布のみからwOBAconを推定する
まず、単純な方法として、角度と速度を別々に考えて、それぞれの分布だけから各打者において打球価値にどれくらい影響があったかを考えていきます。
まず速度の違いを無視して、角度だけを考えます。冒頭では2.5°ずつに打球価値の平均値を示しました。これを使います。まず、極端な具体例で考えてみます。VottoとStantonに出てきてもらいましょう。それぞれの打者の速度と角度の、平均とSDを示します。
この二人は平均角度 (angle_mean) はほとんど同じで、角度のSD (angle_sd) がかなり違います。VottoはMLB全体で見ても非常に角度のSDが小さい打者で、逆にStantonは角度のSDが大きい打者です。
角度のSDが小さいということは、各打球のそれぞれの角度の値が平均角度に近いところにあった、ということです。下はVottoとStantonの打球角度の分布を示しています。
Aは縦軸に打球数をとったヒストグラムで示しています。これでは両者の比較は難しいかもしれません。Bは密度分布を示しています。縦軸は大まかには、横軸で示した角度になる確率を示しています。Votto (青) はStanton (ピンク) に比べて角度が非常に大きい、あるいは小さい打球が少ないことがわかります。縦の赤の点線は0°あるいは37.5°を示していますが、これはこの領域である程度以上打球価値が高いため、目安としてこの部分に線を引きました。これを見ると、VottoはStantonより価値が高い部分でかなり打球の割合が多かったことがわかります。これは、もっと価値が高い10°-30°にしても同じような結果になります。SDは平均から離れている程度を示しており、平均付近は打球価値が高いわけですから、このような結果になります。
ここで、速度を無視して、打球を角度だけから評価して、二人の打者の結果を比べてみます。つまり、冒頭で示した角度ごとの価値をそれぞれの打球に当てはめて、その平均を計算するということです (注1)。
角度のみから推定されたwOBAconはVottoのほうがStantonより0.1も高くなりました。Vottoは角度の観点から見て、価値の高い打球をたくさん打っていたため、このような結果になったと考えられます。実際のwOBAconは3列目の"wOBAcon"で示しています。Vottoの推定値はwOBAconとしてはかなり優秀な0.451で、Stantonの推定値は平均以下程度の0.356となりました。これはVottoのように角度を狭く保つことの価値を示しているといえるかもしれません。MLB全体でのwOBAconの分布を示します。
Vottoの推定値0.45は、実際のwOBAconで考えると、全体で見てもかなり優秀であることがわかります。
Vottoについては実際のwOBAconと、角度から推定されたwOBAconは概ね一致しましたが、Stantonは大きく過小評価しています。これはVottoは速度の平均やSDがほぼMLB平均であり、一方Stantonは平均速度や速度SDが平均から大きく乖離しているためだと考えられます (前の項 [#標準偏差] の最後で示したヒストグラムと比較してください)。つまり、Stantonは角度の部分からは平均以下程度の価値しか得られていないのですが、速度が大きいために角度が望ましい部分での価値を更に高めたり、あるいは多少角度が悪くなってもスタンドまで持っていったりできる力があるために全体的に良い成績になっていただろう、ということです。この角度だけを使った推定値は、速度を無視している現実を無視した欠陥指標ですが、仮に全員が同じような打球速度を持っていたら? というありえない、特定の要素に注目した質問にざっくりと答えてくれます。
ここで、この角度だけから推定した価値を各選手の全打球から計算し、各選手について角度の平均値とSDとの関係を見てみましょう。
AとBを比較すると、角度のSDは平均よりも、角度だけから考えた価値に影響が大きかったように見えます。この角度SDの低下による打球価値上昇の効果は、よくある打球分類で表現してみるとおそらくLDの増加とPUの低下によって起こるようです (これは次回示します)。角度の平均値の効果が小さいのは、冒頭の図で見たように平均値は既に価値が高い部分にあるためでしょう。例えば仮に、MLB全体の角度がもっと低ければ、角度を上げる効果は高く推定されたかもしれません。
# 速度分布のみからwOBAconを推定する
同様に速度についても、速度だけを考えた場合にどうなるか見ていきましょう。まず具体例として、PuigとMelky Cabreraの速度分布を示します。この二人は平均速度 (speed_mean) は同じですが、SD (speed_sd) で大きな違いがあります。
赤の点線はかなり価値が高い基準として105 mphを示します。SDが大きいPuigのほうが、105 mph以上の打球が多そうに見えますが、同時に非常に速度が低い75 mph以下の打球も多そうです。
この二人の打球速度から、速度だけを使った推定wOBAconを計算してみます。
Puigのほうがかなり高いwOBAconが推定されました。遅い打球も多くなっていますが、既に説明したように、遅い打球は、平均的な速度の打球と比べて価値がそれほど大きく下がらないという性質があります。このため、遅い打球の増加によってもたらされるペナルティーは、ここではそれほど影響が無かったのかもしれません。速度に関してはSDが大きいこと、つまり平均速度から離れた打球が多いということ、は打球価値を高めることと関連がありそうです。
速度の分布だけから推定されたwOBAconと、速度の平均/SDとの関係を見てみます。
角度の場合と違い、こちらは平均値との関係が強いようです。これは冒頭の全体の分布で見て、平均速度が価値が高い部分よりかなり低かったことと関係があるでしょう。また、速度のSDも角度の平均値よりは影響が大きかったと見えるのではないでしょうか (注2)。ただし、速度のSDは角度平均よりは年度間相関はかなり小さく、仮にここで示された影響の大きさが正しいとしても、打者のスキルの評価として角度の平均のほうが重要である可能性はあるかもしれません (注3)。
# まとめ
打者ごとの打球の性質を表す数値としては平均値がよく語られますが、ここでは分布の広がりについて簡単に見てきました。各打者における速度/角度の分布の広がりは、平均的な打球価値や頻度の分布を見る限り、打球価値に影響を及ぼす可能性が高そうです。また、分布の広がりは選手間で一貫した違いがあり、打者のスキルとして評価できる可能性が高そうです。
ここでは角度、あるいは速度だけに注目して、その分布から価値を推定することを試みました。少なくとも、この角度/速度の一方だけを考慮した方法では、SDはそれなりに推定値に影響がありそうです。極端な具体例としてVottoを示しましたが、彼は平均的な平均角度、平均的な平均速度、平均的な速度SDを持っていますが、角度SDを非常に小さく保つことで、打球価値をMLBでも上位のレベルまで改善させている可能性がありそうです (注4)。
# 速度と角度を同時に考える
しかし、ここで計算した角度、あるいは速度からの推定値には問題があります。それは、それぞれ、速度、角度を無視している点です。両方を「同時に」考えたほうが価値の推定としては妥当性が高いのは明らかでしょう。同時に考える方法はいくつか考えることができ、その一つはStatcastで計算されているxwOBAです。この計算過程では1つ1つの打球について、角度、速度の両方を考慮して各打球の価値 (xwOBA value) を推定しています。各打者でまとめられたxwOBAでも、速度や角度の分布の広がりの違いが反映されているはずです。
上で行った角度と速度を別々に考慮して効果を見積もって、それぞれの効果を足すことで2つの要因を考慮することもできるかもしれませんが、これはやや問題がありうる方法です。この例では要素が多くわかりにくいので、例えば4シームの速度の効果と、スピンの効果を足し合わせる場合を考えてみましょう。
4シームは速度が速いほど、回転速度が多いほど、効果が高いと信じられています。回帰分析を使えば (あるいは適当に幅を区切ってその平均値を計算とかでも)、例えば、
1. 速度を5 mph上げた時に、
あるいは
2. 回転速度を100 rpm上げた時に、
平均的にどれくらい効果があるか、ということがわかるでしょう。
図で示します。
ここではMLB15-18について、4シームを1000球以上投げた投手について、平均速度、平均回転速度、そして得点価値 (PitchValue; 正の値が投手にとって望ましい; 注5) を示しています。Aは横軸に速度、Bは横軸に回転速度をとり、縦軸に各投手での100球あたりでの得点価値を示しています。これらを見ると速度と回転速度のいずれも弱いながらも、価値と正の相関があることがわかります。
ここで、これをそれぞれ計算して足し合わせようとする場合に問題となるのは、速度と回転速度には正の相関があることです (図C)。例えば、Aの図から速度を5 mph上げた効果を速度だけで調べた場合、相関の分だけ (図Cを見ると50 rpm程度でしょうか) 回転速度が上がった効果も同時に取り込んでしまいます。図Bに注目して 同様に調べてもやはり速度との相関も同時に含まれているはずです。このため、別々に調べて足し上げると、効果の一部を重複して評価してしまう可能性があります。
図Dでは横軸で速度を調整して、その予測値 (直線) からの解離の程度と回転速度 (色) と関係性がありそうかどうかがわかるので、速度の効果と独立した回転速度の効果がざっくりとですがわかります。同じ速度であれば、回転速度が大きいほうが得点価値が高そうに見えなくもないのではないでしょうか。このブログでも何度か使っている方法で、数値の正確さは無いですが、これは一応同時に2つの要素を考えていることになります。
という感じで、打球や投球の価値に影響を与える要素が複数あり、それらの要素同士に相関がある場合、個別の評価を足すとおかしな結論が出る可能性があります。上で説明した角度と速度だけから計算した結果も、お互いの相関の効果を含んでいる可能性があり、単純に足してしまうと、重複して評価する可能性があります。
次回はxwOBAとは別の方法で打者ごとの打球の角度/速度の平均値/SDを同時に考慮して、打球結果がどの程度説明できるようになるのかを見ていきます。
続く。
<参考>
Statcast data
https://baseballsavant.mlb.com/about
<RPubs版>
今回ここで書いた内容はほとんど書いていませんが、冒頭の図のコードもあります。
http://rpubs.com/snin/bb_sd_values
http://rpubs.com/snin/bb_sd_values_suppl
_____________________________________________________________________
注1.
実際には、これは現実に起こった結果なので、仮に角度が大きい打球で速度が大きい打球が多かった場合、それを考慮に入れることになる。実際、打球速度が高い選手は打球角度が高い傾向にある。例えば、HRになりやすい30°あたりのピークが速度の非常に高い長距離打者が多く占めているのであれば、平均的な打球速度しか無い打者に対して過大評価を与える可能性があるはず。しかし、VottoとStantonの分布で見られるように、実のところ最大の価値を叩き出せる30°付近も、打球速度が高い打者よりも、角度SDが小さい打者の打球が多いために、平均的な速度で考えてもあまり問題にならないのかも。
注2.
Aを見ると、平均速度が大きい打者 (91.25以上ぐらい) では速度SDからの影響が小さいように見えなくもないかも。これは、実際の打球速度の分布は、
1. 潰れたピークや二峰性のピークをもつことが多い
2. 分布が高速度側に歪んでいる
という事実を考えると、理にかなっているかも。
つまり、同じ平均値を持つ正規分布よりも高速側が多かったり、平均値 (mean) よりも中位値 (median) が高めに出やすい。そのため、各打者の平均速度は最大で95程度で、100-105 mphよりはかなり小さいですが、単純に平均値から考えるよりは十分に速度が高い打球を含んでいる可能性がある。中位値を使う、価値に変換して使う、などのほうが問題は小さくなるかもしれません。
より打球速度が速いペアで、かつ平均値が近くSDに差があるOrtizとStantonに関してデータを示しておきます。
ちなみに速度に関する歪度の年度間相関は0.24程度で、打者間の差はあまり一貫性がなさそうです。
注3.
平均角度はスキルというよりはアプローチの結果と見たほうがいいだろう、というのがTangoのスタンスのようです。個人的にもそんな感じがします。
Tango,
Statcast Lab: Do Successful Launch Anglers keep Angling?, 2018.
http://tangotiger.com/index.php/site/comments/statcast-lab-do-launch-anglers-keep-angling
そもそも打者から見てそれなりに好ましい位置にある時点で、全体的に見れば打者側のコントロールが強いのは明らかな感じがします。
で、強いコントロールのもとで、それぞれの打者は自分に適した角度を探していて、その結果個人差がある、的なイメージでしょうか 。角度が高いのも、低いのも、ちゃんとそれなりに理由がある。アプローチとの関係は、下で引用している記事とも関連がある話です。
注4.
Vottoに関する記事。
Zach Buchanan,
Joey Votto: I want to be 'unpitchable', 2017.
https://www.cincinnati.com/story/sports/mlb/reds/2017/04/27/joey-votto-want-unpitchable/100991956/
一部引用。
He sees the swing-change benefit for some players – athletic hitters with natural power who have yet to really tap into it. J.D. Martinez, A.J. Pollock and Mitch Haniger all have enjoyed success with the “Groundballs Suck” approach. But Votto worries that it’s a fad, and that less successful players will waste their careers chasing a swing that works only for a select few.
引用とは離れますが、adaptabilityの話と、GB/FB platooningの効果 (The Book参照) と、Vottoの角度SDが低いことを合わせると一つの仮説が出てきます。つまり、角度の平均値を投手のタイプによってシフトさせて (GB投手にはFB打者っぽい角度、FB投手にはGB打者っぽい角度を取る) 打者にとって望ましい効果を得ており、その結果全体で見れば角度SDが小さくなる可能性。しかし、少なくともVottoに関しては、GB投手に対して平均値を高めにシフトしている可能性はもしかしたら少しはあるかもしれないけど、GB投手/FB投手/それ以外のどのタイプに対しても角度SDが低そう。
またそもそも、簡単なサンプリング実験で、対戦相手タイプによる平均値の変化を小さくしても全体のSDにはほとんど影響がない。これはおそらくSDの数値が対戦相手のタイプによって生じる平均値のシフトより大きすぎるため。というわけで角度のSDとGB/FB platooningの関係仮説はほぼボツ。思いついたときは、面白いかもって思ったんですけどね。。アイデアに定量性が無さ過ぎ。
GB/FBの相性はL/Rの効果に比べて、打者がアプローチ次第で制御できる部分が大きそうな気もしたんですが、なんだかんだ難しそうな感じも。
注5.
Pitch Value (PV) の計算ではイベント、及びカウントの得点価値は、基本的にはRetrosheetから計算したMLB 2005-2008のものを使っています。うちのPVはFangraphsのものと比べるとやや高めに出る傾向がある (原因はよくわからない)。また、ここでは打球部分だけxwOBA valueを得点価値に変換して使用しています (なのでxPV)。
Retrosheetから持ってくるよりStatcastの中で計算してしまったほうが、他の人が再現性を取るのが容易なので望ましいかもしれません。あるいはFangraphsからそのまま取ってきて合わせるとか。Analyzing Baseball Data with Rのchap. 12 (1st edition) でHanphreysのWizardryとFangraphsのデータを連結するために記述されている、stringdistなどを使う方法で簡単にできます。
https://github.com/maxtoki/baseball_R/blob/master/scripts/Chap12.packages.R
2版がamazonからまーだ届いてないんですが、githubページはここのようです。
https://github.com/beanumber/baseball_R